
Selected Papers - CoRL 2019
Deep Value Model Predictive Control
-
Motivation
the sparsity of the reward and potential non-differentiability rule out the possibility of using Trajectory Optimization (TO) -
Goal
combine model-based and sample-based approaches to exploit the knowledge of the system dynamics while effectively exploring the env -
MPC - a model-based Trajectory Optimization approach
MPC truncates the time horizon of the task, continually shifts the shortened horizon forward, and optimizes the state-input traj based on new state measurements -
MPC disadvantage
(1) relatively high computational cost
(2) the optimization time horizon is often kept short
(3) therefore, prevents it from finding temporally global solutions
(4) heavily relies on the differentiability of the formulation
(5) hard to deal with sparse and non-continuous reward/cost signals -
DRL advantage and disadvantage (+) good in long-horizon tasks with sparse rewards
(+) even in continuous control domain
(-) requires enormous data
(-) suffers from the exploration-exploitation dilemma -
DMPC - an actor-critic approach <-proposed method
actor: an MPC policy
critic: a value function learner
the MPC actor interacts with env and collects samples to update Value critic
the Terminal Cost of MPC is determined by the estimated Value critic
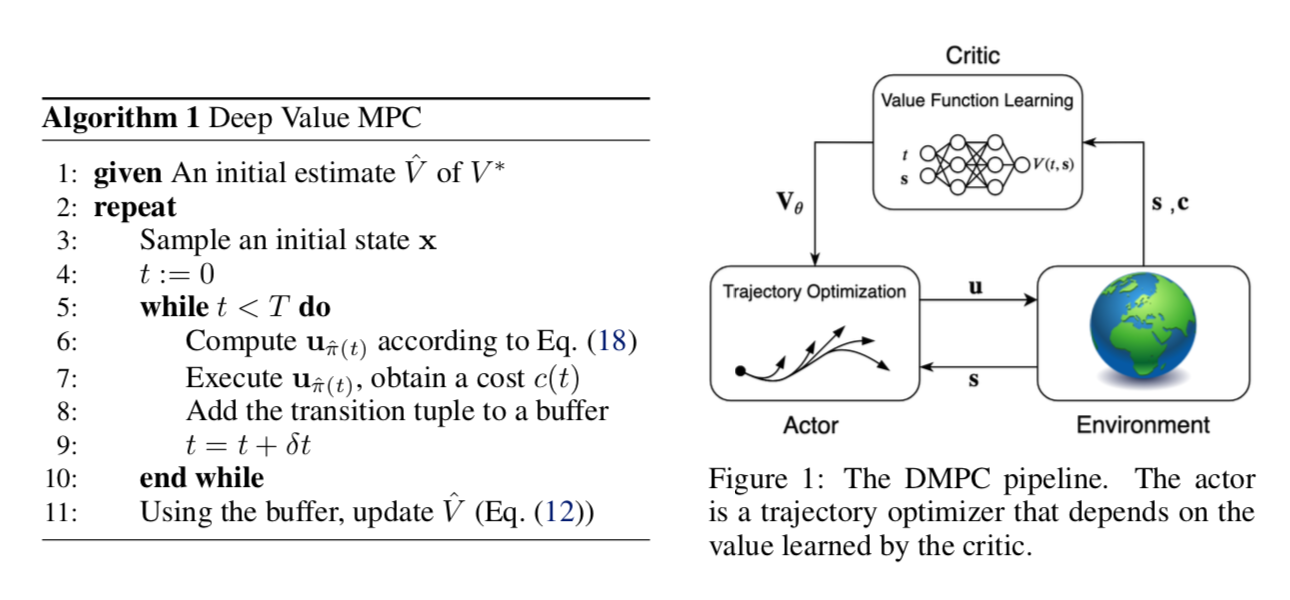
- Contribution
(1) an in-depth analysis of the bilateral effect of DMPC
(2) show that the MPC actor is an importance sampler that minimizes an upper bound of the cross-entropy to the state traj distribution of the optimal sampling policy
(3) transform an initially stochastic task into a deterministic optimal control problem
(4) empirically validate that defining a running cost instead of the heuristic function accelerates the convergence of the value function, which makes DMPC good at sparse reward function
An Online Learning Procedure for Feedback Linearization Control without Torque Measurements
-
Motivation
the estimation of the robot dynamic model is usually performed offline, therefore, changes in the structural parameters will restart the identification procedure from scratch, especially during robot’s interaction with other objects (i.e. payloads to the end-effector, collision detection, reaction strategies adopted during motion) -
Related approaches - using regression
(1) direct dynamic model learning - how the system, given its actual state, responds to a certain input, i.e.
[10] learn the transition probability model
[12] reconstruct the system nonlinear dynamics with GP
[13] use a regressor as predictive model for nonlinear MPC
(2) inverse dynamic model learning - estimating the input that needs to be given to the system in order to achieve a certain desired new state -
Goal
use a linear MPC, but designed a procedure for learning the inverse dynamic model
learn the unmodeled dynamics to improve the feedback linearization process without the use of any joint torque measurements, which are known to be noisy -
Proposed method
a method to reconstruct dynamic model uncertainties and parameters variations by means of an online Gaussian Process Regression -
Torque measurements problem
affected by high level noise, typically higher than the noise added to the measures coming from the encoders which return joint positions -
Problem formulation

-
Learning procedure
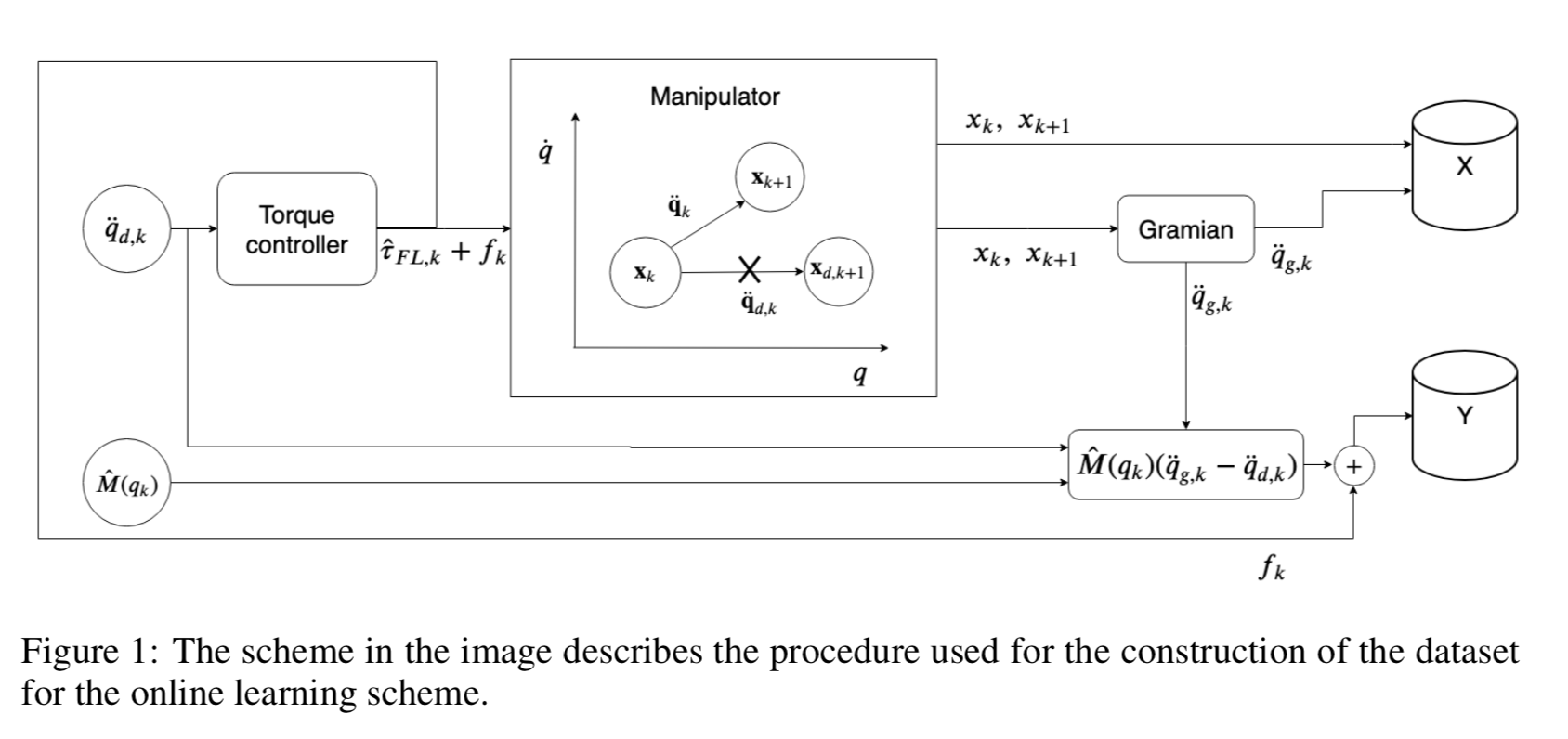
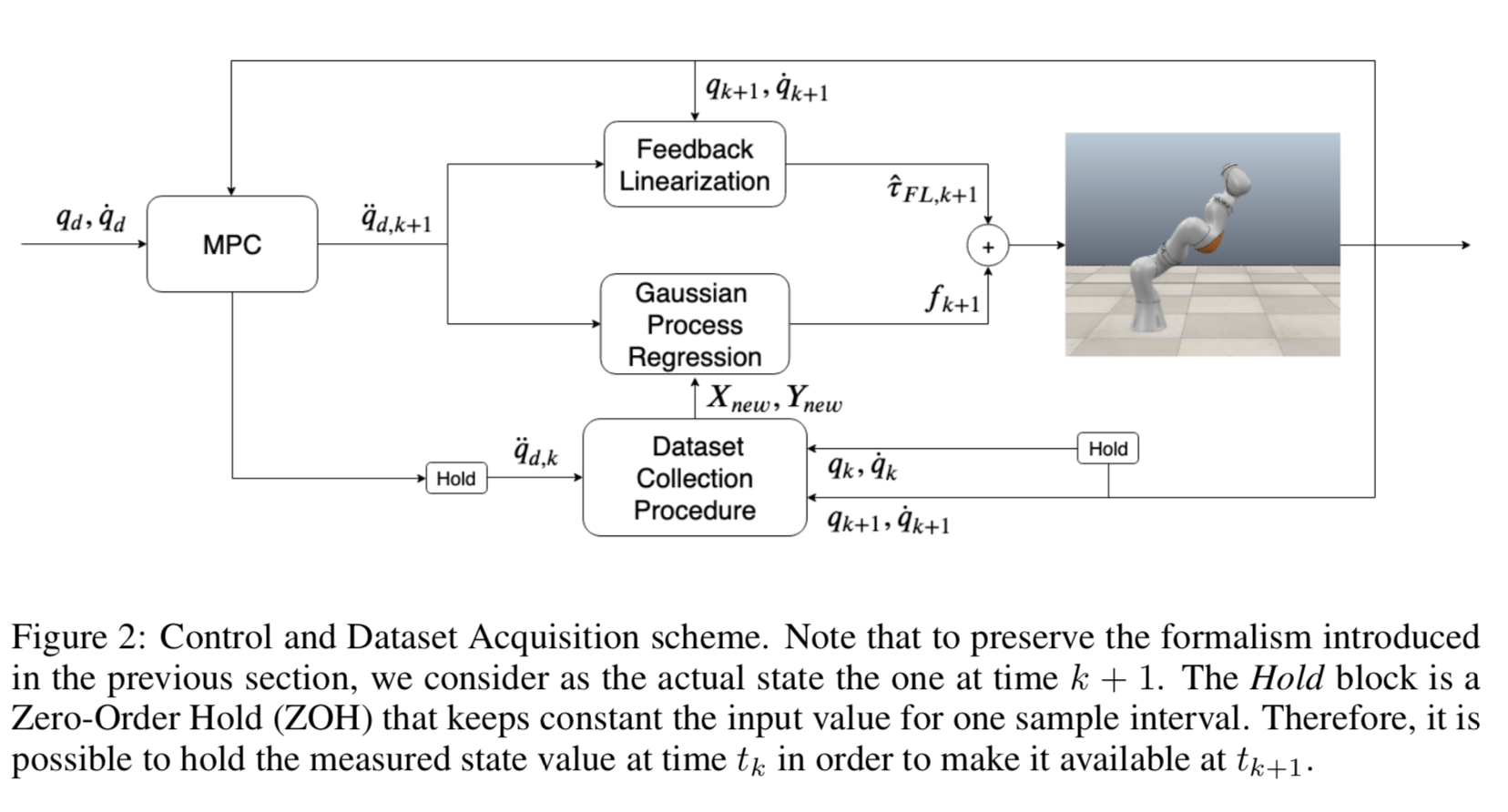
- Contribution
(1) a new approach for online learning the exact FL of a manipulator while executing a predefined task
(2) the method is composed by a dataset collection procedure designed to reconstruct the unmodeled dynamics
(3) and by a controller that computes the commanding joint torques according to a desired trajectory
(4) small dataset -> employ GP regression to learn the unmodeled dynamics
(5) the Controllability Gramian is used for computing the joint’s accelerations
(6) shows it is possible to improve the model by exploiting only joint position measures without the need of any joint torque data
(7) therefore, can obtain a reliable estimate of dynamic uncertainties
Curious iLQR: Resolving Uncertainty in Model-based RL
-
MBRL framework with curious iLQR <- proposed method
MBRL combines Bayesian modeling of the system dynamics with iLQR, an iterative LQR approach that considers model uncertainty
during trajectory optimization the curious iLQR attempts to minimize both the task-dependent cost and the uncertainty in the dynamics models -
Motivation: Model-based promise and challenge
(+) sample-efficiency
(-) the learned model generalizes beyond the specific tasks used to learn it
-> the curiosity/exploration can help!! -
Curiosity definition
motivation to resolve uncertainty in the env -
Hypothesis
by seeking out uncertainties, a robot is able to learn a model faster and therefore achieve lower costs more quickly
MAT: Multi-Fingered Adaptive Tactile Grasping via Deep Reinforcement Learning
-
Vision-based grasping problems
typically adopt an open-loop execution of a planned grasp can cause failures including
(1) ubiquitous calibration error
(2) grasp slip
(3) low friction
(4) adversarial object shapes
(5) recovery from a failed grasp is difficult by visual occlusion -
Closed-loop grasping
continuously adjusting the robot’s dofs to improve the quality of the current grasp based on sensory feedback
(+) enables the robot to correct the initial grasp to achieve ever higher pick-up success rates, given an approximately correct initial grasp post
(-) requires a sensor modality that is free of external disturbances and accurate state of the current grasp
therefore, vision info (RGB,RGB-D) is difficult to use due to vision occlusion
-> Tactile info!! -
Tactile merits
(1) rich in info with many sensor cells on each finger
(2) free of external disturbances -
MAT <- proposed method
a tactile closed-loop method capable of realizing grasps provided by a coarse initial positioning of the hand above an object
(1) allows to learn grasp action primitives in a generative manner via maximum entropy deep RL
action primitives include
i) decisions of granular movements of each of the fingers, lifting the end-effector for pick-up
ii) reopening the fingers and adjusting the end-effector position and orientation
(2) MAT overcomes the transfer from sim2real in a high fidelity way by choosing observation and action modalities that maintain small sim2real gaps to real world, such as joint angles, binary tactile contacts, tactile contact Cartesian locations, etc -
Maximum entropy DRL difficulty requires high sample complexity and training experiences that are diverse in terms of object types, quantities, poses, and clutter levels
therefore direct learning/transfer learning in real-world becomes difficult -
Features of MAT
(1) use tactile and proprioceptive info
(2) 5 finger motions and larger regrasp movements
(3) a novel curriculum of action motion magnitude
(4) careful selection of features that exhibit small sim-to-real gaps
Refs
-
MPC refs in robotics:
[1] K. Alexis, C. Papachristos, G. Nikolakopoulos, and A. Tzes. Model predictive quadrotor in- door position control. In 2011 19th Mediterranean Conference on Control Automation (MED), pages 1247–1252, June 2011. doi:10.1109/MED.2011.5983144.
[2] F.Farshidian,E.Jelavic,A.Satapathy,M.Giftthaler,andJ.Buchli.Real-timemotionplanning of legged robots: A model predictive control approach. In Humanoids, pages 577–584, 2017. doi:10.1109/HUMANOIDS.2017.8246930.
[3] J. Koenemann, A. D. Prete, Y. Tassa, E. Todorov, O. Stasse, M. Bennewitz, and N. Mansard. Whole-body model-predictive control applied to the hrp-2 humanoid. In IROS, pages 3346– 3351, 2015. -
Learning direct dynamics model by regression refs:
[10] M.Deisenroth,D.Fox,andC.EdwardRasmussen.Gaussianprocessesfordata-efficientlearn- ing in robotics and control. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37:408–423, 02 2015. doi:10.1109/TPAMI.2013.218.
[11] S. Kamthe and M. Deisenroth. Data-efficient reinforcement learning with probabilistic model predictive control. In Proc. of the International Conference on Artificial Intelligence and Statis- tics (AISTATS), 2018.
[12] F. Berkenkamp and A. P. Schoellig. Safe and robust learning control with gaussian processes. In 2015 European Control Conference (ECC), pages 2496–2501, July 2015. doi:10.1109/ECC. 2015.7330913.
[13] C. Ostafew, A. Schoellig, and T. D. Barfoot. Robust constrained learning-based NMPC en- abling reliable mobile robot path tracking. The International Journal of Robotics Research, 35, 05 2016. doi:10.1177/0278364916645661. -
Learning inverse dynamics model by regression refs:
[14] Z. Shareef, P. Mohammadi, and J. Steil. Improving the inverse dynamics model of the KUKA LWR IV+ using independent joint learning. IFAC-PapersOnLine, 49(21), 09 2016.
[15] T. Waegeman, F. Wyffels, and B. Schrauwen. Feedback control by online learning an inverse model. Neural Networks and Learning Systems, IEEE Transactions on, 23:1637–1648, 10 2012. doi:10.1109/TNNLS.2012.2208655.
[16] J. Umlauft, T. Beckers, M. Kimmel, and S. Hirche. Feedback linearization using gaussian processes. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 5249–5255, Dec 2017. doi:10.1109/CDC.2017.8264435.
[17] D. Nguyen-Tuong, M. Seeger, and J. Peters. Computed torque control with nonparametric regression models. In 2008 American Control Conference, pages 212–217, June 2008. doi: 10.1109/ACC.2008.4586493.