
Control as Inference
Introduction
the Equivalence
probabilistic inference
under deterministic dynamics - - a generalization of RL
| <=> max entropy RL |
variational inference - - optimal control problem
under stochastic dynamics
Probabilistic Graphical Models (PGMs)
- provide a consistent and flexible framework to devise principled objectives
- set up models that reflect the causal structure
- allow a common set of inference methods to be deployed against a broad range of problem domains
!!setting a learning problem as a PGM is the crucial step to solve it
Motivation of connecting PGM and RL/control
probabilistic models + reward/utility => decision making/optimal control/RL
Formalize decision making as inference in PGM can
(+) allow the use of approximate inference tools
(+) extend the model in flexible and powerful ways
(+) reason about compositionality and partial observability
Similar literature:
[3] the Kalman duality
[4] maximum entropy RL
[5] KL-divergence control
[6] stochastic optimal control
Formulates RL/decision making as inference can provide
(+) a natural exploration strategy based on entropy maximization
(+) effective tools for inverse RL
(+) the ability to deploy approximate inference algorithms to solve RL problems
(+) appealing probabilistic interpretation for the meaning of the reward function and its effect on the optimal policy
Reward design in RL sometimes
(-) blurs the line between algorithm and objective with task-specific heuristics and task objectives combined into a single reward
In the control as inference framework
reward induces a distribution over random variables
optimal policy aims to explicitly match a probability distribution defined by the reward and system dynamics
-> suggest a way to systematize reward design
A Graphical Model for Control as Inference
PGM <=> RL objective + an entropy term
the Decision making problem
RL problem formulation

Questions:
How can we formulate a PGB such that the most probable trajectory corresponds to the trajectory from the optimal policy?
Or How can we formulate a PGM such that inferring the posterior action conditional p(a_t|s_t,theta) gives us the optimal policy?
Introducing reward

Explanation:
Suppose with a deterministic dynamic system, where the “Dynamic probability” term is a constant for all trajectories that are dynamically feasible.
Then, the trajectory with the highest reward has the highest probability, and trajectories with lower reward have exponentially lower probability.
Policy search as Probabilistic inference
We can recover the optimal policy using a standard sum-product inference algorithm
analogously to inference in HMM-style dynamic Bayesian networks

Now we have the solution but the intuition, the intuition can be recovered by the equations in log space

being “soft” is optimistic:
if among the possible outcomes for the next state, there is one outcome with a very high value, it will dominate the backup, even when there are other possible states that might be likely and have extremely low value
-> creates risk seeking behavior: if an agent behaves according to this Q-function (soft backup), it might take actions that have extremely high risk, so long as they have some non-zero probability of a high reward
the Objective

Variational Inference and Stochastic Dynamics
issues with Stochastic dynamics
The nature problem of max entropy framework under stochastic dynamics is the assumption that the agent is allowed to control both its actions and the dynamics of the system in order to produce optimal trajs, but its authority over the dynamics is penalized based on the deviation from the true dynamics.

The posterior doesn’t necessarily match the true dynamics, therefore the agent assumes it can influence the dynamics to a limited extent.
A simple fix:

Max Entropy RL with Fixed dynamics
To optimize the objective under stochastic dynamics, we need to derive the backward messages from an optimization perspective as dynamic programming

if we fix the dynamics and initial state distribution, and only allow the policy to change, we recover a Bellman backup operator that uses the expected value of the next state, rather than the optimistic estimate (the soft one Q(s,a)=r(s,a)+logE[exp(V(s’))])
connection to structured Variational inference

Approximate Inference with Function Approximation
Max Entropy Policy Gradients

The resulting policy gradient estimator exactly matches a standard policy gradient estimator, with the only addition of the -log q_theta(at’|st’) term (the square term) to the reward at each time step t’
Intuitively, the reward of each action is modified by subtracting the log-probability of that action under the current policy, which causes the policy to maximize entropy
Max Entropy Actor Critic
Instead of directly differentiating the variational lower bound, we can adopt a message passing approach which can produce lower-variance gradient estimates

Note, the V and Q correspond to the values of the current policy q(at|st) rather than the optimal V* and Q*
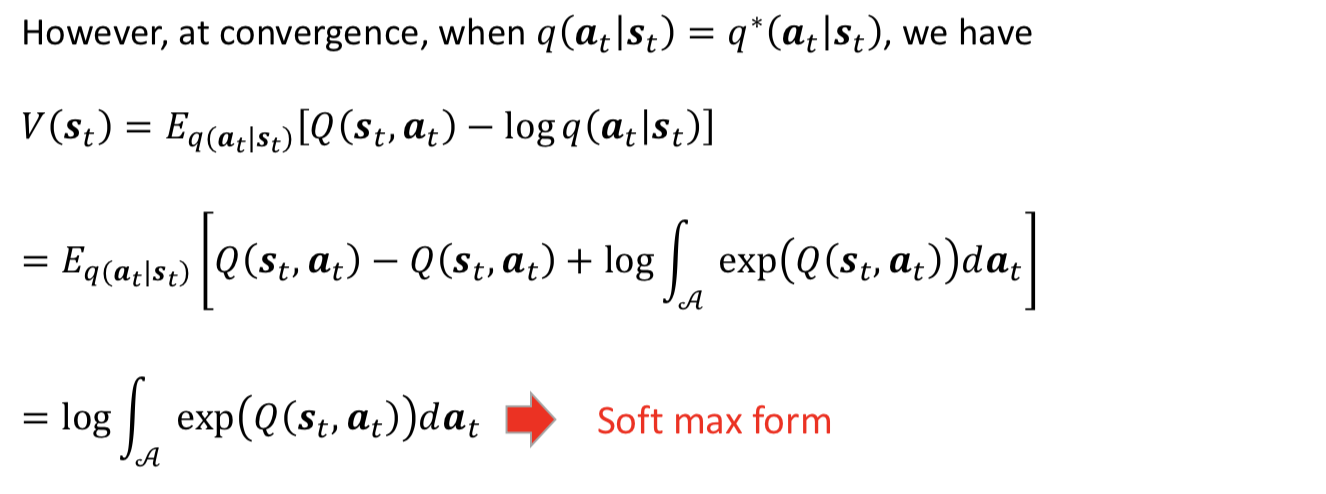
We now see the optimal variational distribution for q(at|st) can be computed by passing messages backward through time, and the messages are given by V(st) and Q(st,at)

- it suggests that it may be beneficial to keep track of both V(st) and Q(st,at) networks. it’s reasonable in a message passing framework and benefit target network for practical usage, where the updates to Q and V can be staggered or damped for stability
- it suggests that policy iteration or actor-critic might be preferred (over q learning), since they explicitly handle both approximate messages and approximate factors in the structured variational approximation
see soft actor critic [7]
Soft Q-learning
We can derive an alternative form for a RL algorithm without using an explicit policy parameterization, fitting only the messages Q_parameter(st,at)

connection between soft Q and policy gradient
see Reinforcement learning with deep energy-based policies [8]

References
[1]Levine, Sergey. “Reinforcement learning and control as probabilistic inference: Tutorial and review.” arXiv preprint arXiv:1805.00909 (2018).
PGM
[2]Koller, D. and Friedman, N. (2009). Probabilistic Graphical Models: Principles and Techniques. The MIT Press.
PGM and RL/Control
[3]Todorov, E. (2008). General duality between optimal control and estimation. In Conference on Decision and Control (CDC).
[4]Ziebart, B. (2010). Modeling purposeful adaptive behavior with the principle of maximum causal entropy. PhD thesis, Carnegie Mellon University.
[5]Kappen, H. J., Gómez, V., and Opper, M. (2012). Optimal control as a graphical model inference problem. Machine Learning, 87(2):159–182.
Kappen, H. J. (2011). Optimal control theory and the linear bellman equation. Inference and Learning in Dynamic Models, pages 363–387.
[6]Toussaint, M. (2009). Robot trajectory optimization using approximate inference. In International Conference on Machine Learning (ICML).
Soft Actor Critic
[7]Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018b). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In arXiv.
Soft Q learning
[8]Haarnoja, T., Tang, H., Abbeel, P., and Levine, S. (2017). Reinforcement learning with deep energy-based policies. In International Conference on Machine Learning (ICML).